A typical web search engine functions on the following pattern:
I. Web crawling
II. Indexing
III. Searching
Search engines operate by saving data of a number of web pages they access from the HTML collection of the pages that are saved / received by a Web crawler, also known as a “spider”. A spider is a programmed Web crawler that tags on every link on the website. The owner of the site has the option to prevent certain pages with the help of robots.txt.
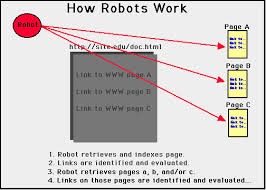
As a next step, the web search engine explores the data on every page to analyze the way it should be indexed. For instance, text can be scrutinized out of the titles, headings, page material, or specific area known as “meta tags”. Information regarding web pages is saved in an index based database to be used in subsequent queries. The query given by a user could consist of a single word in most of the cases.
The index aids in retrieving data pertaining to the query in no time. Certain web search engines, e.g. Google, save the entire source page or part of it as cache memory in addition to storing data regarding those pages while others, e.g. AltaVista, feed the whole text of each page they encounter. Such cache pages permanently contain the originally searched textual data because this is the material which had been originally indexed therefore this could be potentially handy by the time the data over the running page is detected as a kind of inkrot, consequently, its treatment at Google enhances usability by meeting user expectations such that the search terms could be retrieved in the webpage so regained.
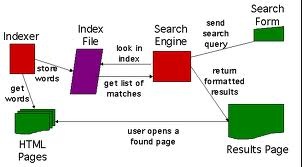
The phenomenon qualifies the principle of least astonishment; this is because the user usually anticipates that the search terms could be contained by the pages returned during the process. Added search connections render those pages in cache quite practical in view of their bearing information which won’t be available any more anywhere.

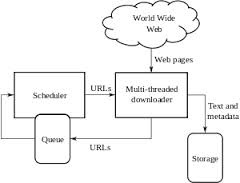
(High level architechture of a standard web crawler from the courtesy of Wikipedia)
The moment an operator feeds a enquiry into the engine, mainly with the help of keywords, the search engine scans its index and offers a catalog of more-or-less resembling web pages as per its standards, normally having a brief profile bearing the title of the document and fragments of the text oft-times. The indexing is constructed on the basis of the information fed with the data and the modus operandi with which the data is catalogued.
(n.b: To access more on digital literacy you may click on the following link of mine. Read, like, share and comment as you please. Please also don’t forget to subscribe me, thank you!)
http://www.filmannex.com/blog-posts/azan-ahmed
By
Azan Ahmed
Blogger: FilmAnnex


